【LLM】CT增量训练调研 - 2024W17
TLDR
- 合理是增量训练方案?
- 不增加tokenizer
- 增加tokenizer
- 评估?
- 中文评估集
- 已有的英文指标
CT分享
- D-CPT Law分享
- 超参数对law是影响:WSD、高和宽
- general knowledge只需要占比5%,不用太多?
- coe:开源model综合用
- CT的评估:评估是很重要的
- base的评估问题:prompt敏感、few-shot
- 经常出现有些指标高、有些指标低
- base的刷分现象
- long context
- Pretrain本身已经具有long context能力,cpt改变attention的分布。domain specific llm也是类似,调整general llm的attention分布。
- 中英更偏底层、cross domain更偏上层?
LlamaFamily
- 扩展词库至65,000个单词
openbuddy
- 增加了共计约17k个CJK字符、中文常用词组。
- 借助RoPE-Scaling模型上下文倍增、FP8 KV-Cache压缩等技术,增加context
OpenChat
- OpenChat 3.5 was trained with C-RLFT on a collection of publicly available high-quality instruction data(没做增量预训练), with a custom processing pipeline. We detail some notable subsets included here:
- OpenChat ShareGPT
- Open-Orca with FLAN answers
- Capybara 1 2 3
- GOAT
- Glaive
- MetaMathQA
- MathInstruct
- OpenAssistant
tigerbot
- The original vocabulary size is 32k, we expand to near but not exceeding 65k
- zh:en roughly 5:5
- In the pretraining stage, we mix in 2-5% (of pretraining data) instruction completion data, preprocessed into an unsupervised format, e.g., {instruction}+"\n"+
- learn some patterns of instruction following
- alignment learning can be lightweight
Linly
- 扩充了 8076 个常用汉字和标点符号
- embedding 和 target 层使用这些汉字在原始词表中对应 tokens 位置的均值作为初始化
- 课程学习(Curriculum learning)训练策略,在训练对初期使用更多英文语料和平行语料,随着训练步数增加逐步提升中文数据对比例,为模型训练提供平缓的学习路径
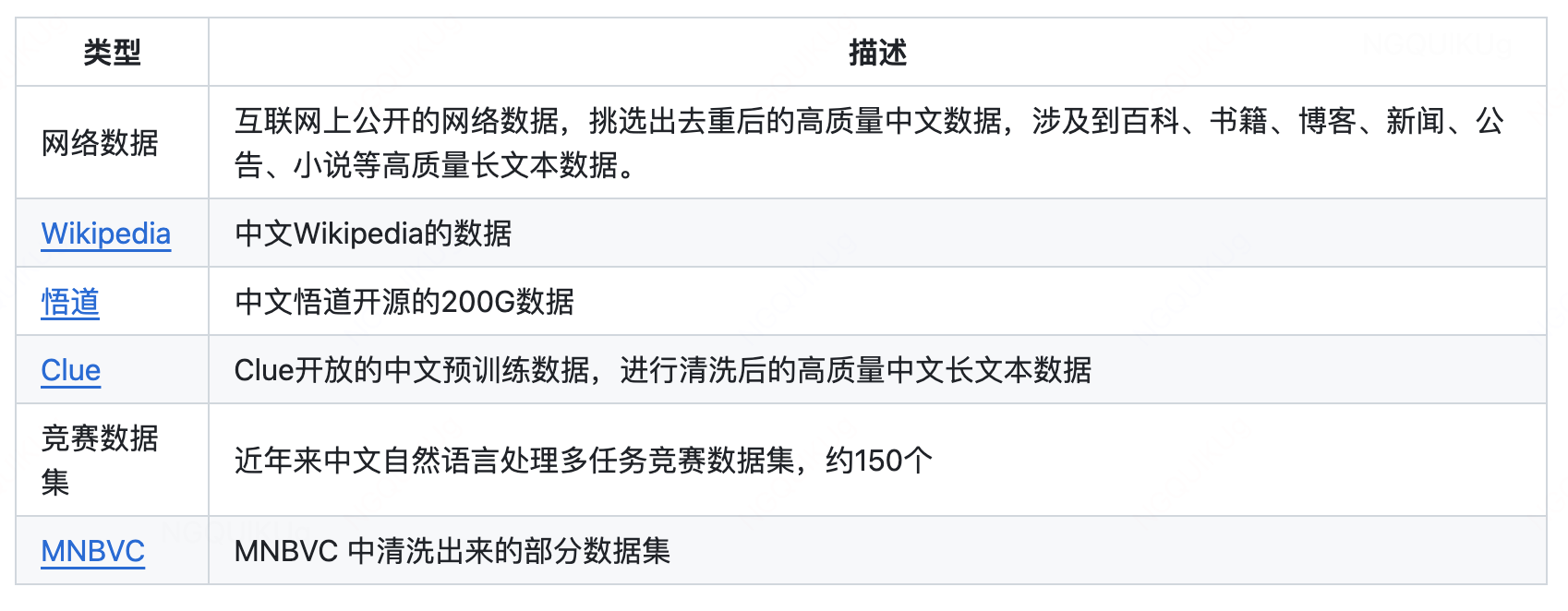
数据探查
- Top5召回率的方式:
- Prompt探测
- 背诵xxx
- 给出开头,直接续写

方案汇总
- CT方案
- 不扩词表
- 扩词表
- Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
- 三分之一的min lr设置
- training data: 100B
- adding 11,176 japanese subwords:he vectors for the embedding and output layers of the added subwords were initialized with the average of the vectors of the subwords segmented by the LLaMA tokenizer
- 扩词表performance:词汇扩展带来的训练文本量的增加并不会直接影响性能。在处理较长语境的任务中,词汇扩展的效果为负向。
- 平行语料:没有证据表明平行语料库促进了跨语言迁移并提高了翻译以外的能力。
- Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
- tokenizer的研究
- Getting the most out of your tokenizer for pre-training and domain adaptation
- when fine-tuning on more than 50 billion tokens, we can specialize the tokenizer of a pre-trained LLM to obtain large gains in generation speed and effective context size.(50B数据就可以扩增字典?)
- Tokenizer Choice For LLM Training: Negligible or Crucial?
- Getting the most out of your tokenizer for pre-training and domain adaptation
- 调整model结构
- MOE方案
- Switch Transformer:topk=1、aux loss
- upcycling:openreview.net/pdf?id=T5nUQDrM4u
- mod:[2404.02258] Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
- 增加layer
- LLAMA PRO: Progressive LLaMA with Block Expansion
- 不足:缺少跨语言能力扩展实验。只是在llama2 7b上的实验
- 目标:enhance domain-specific abilities(编程和数学)
- 每M个layer增加P个layer
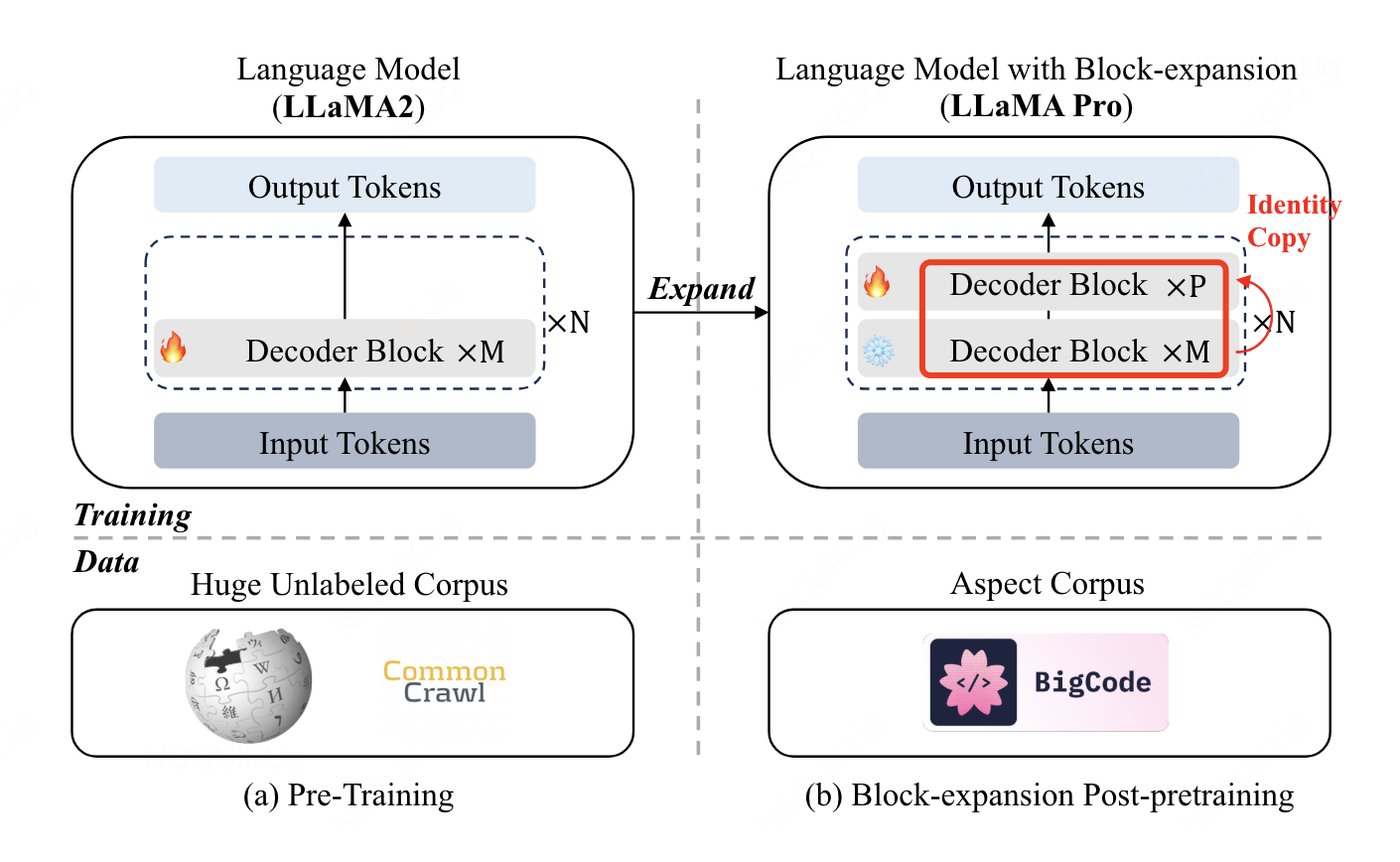
- initializing the output linear matrix to zero in order to preserve the output from the base LLaMA model.
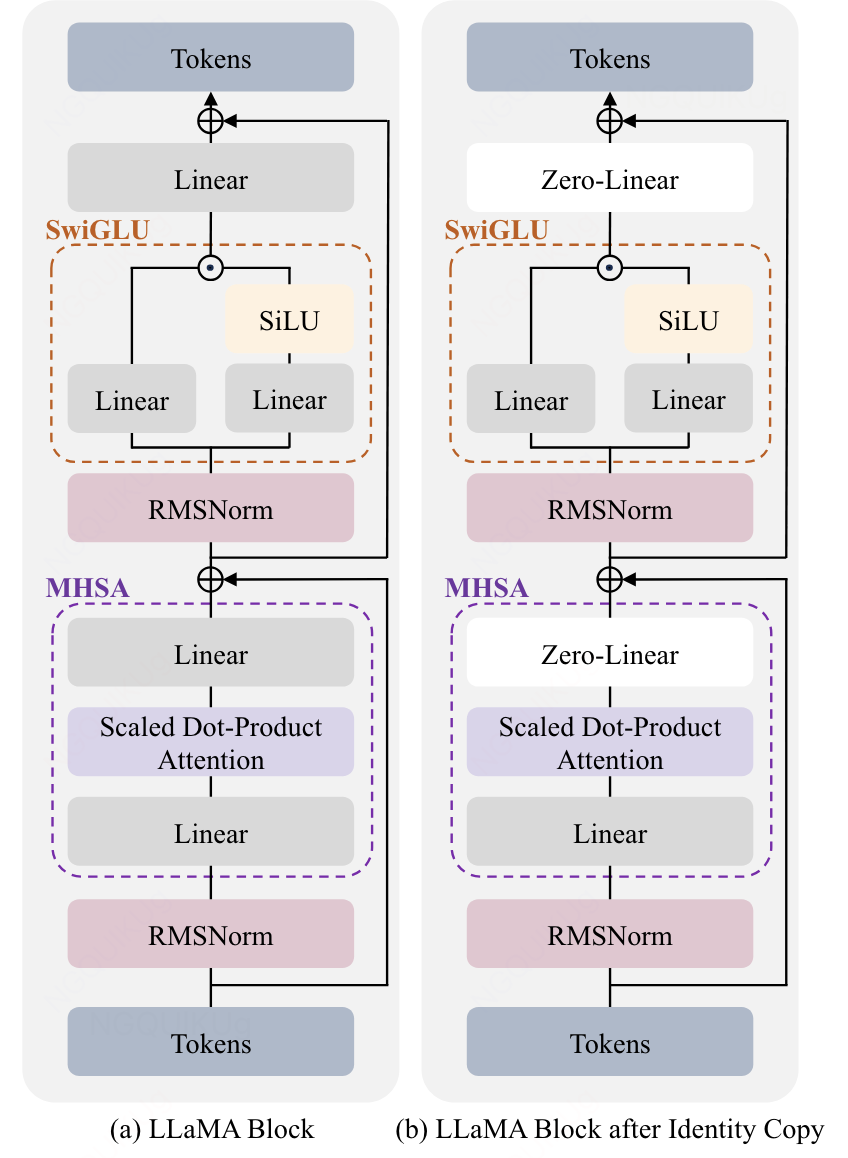
- 增加的层越多,train loss越低
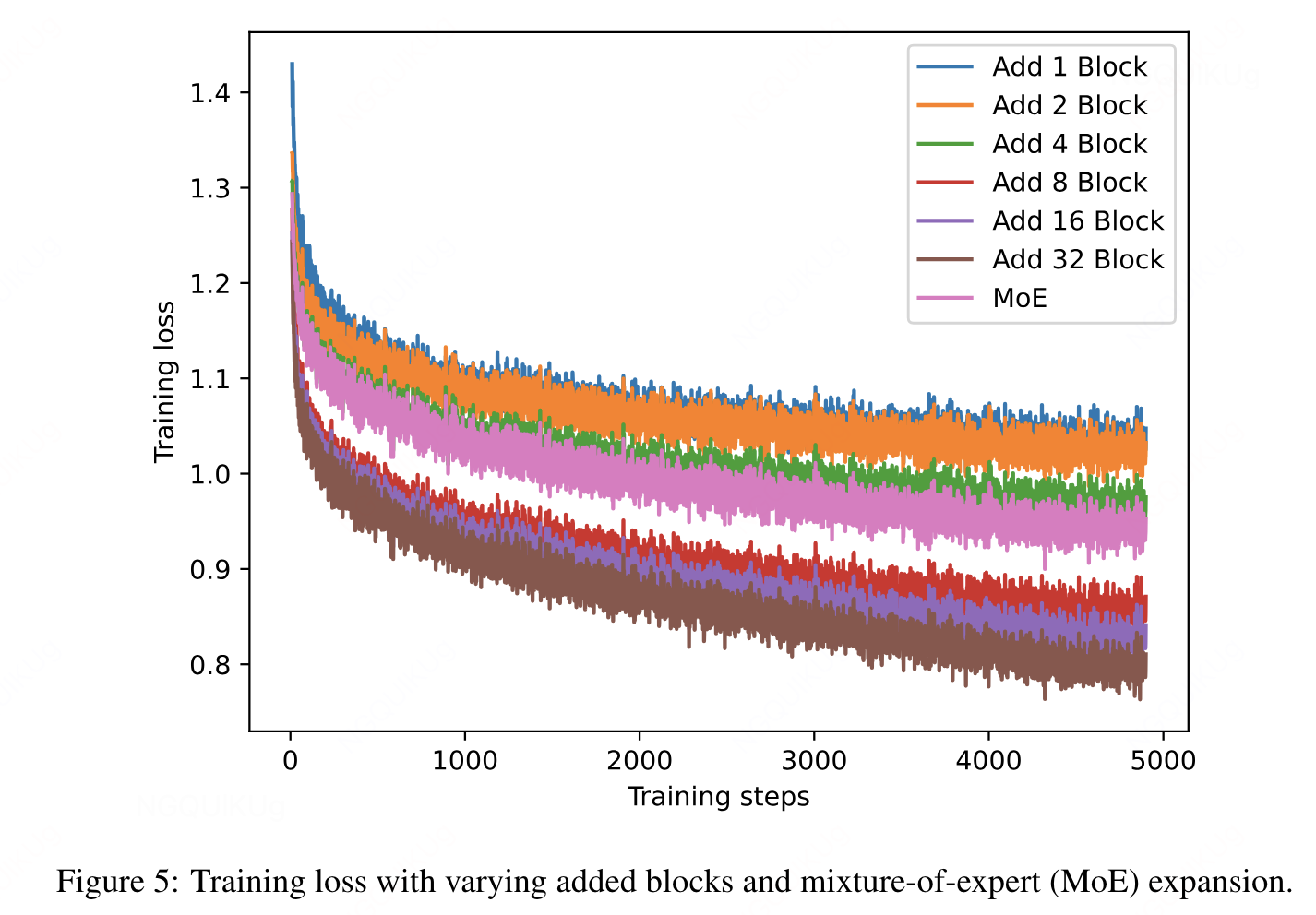
- 增加8layer效果最好,llama2 7b共32layer。明显好于moe和suffix stacking
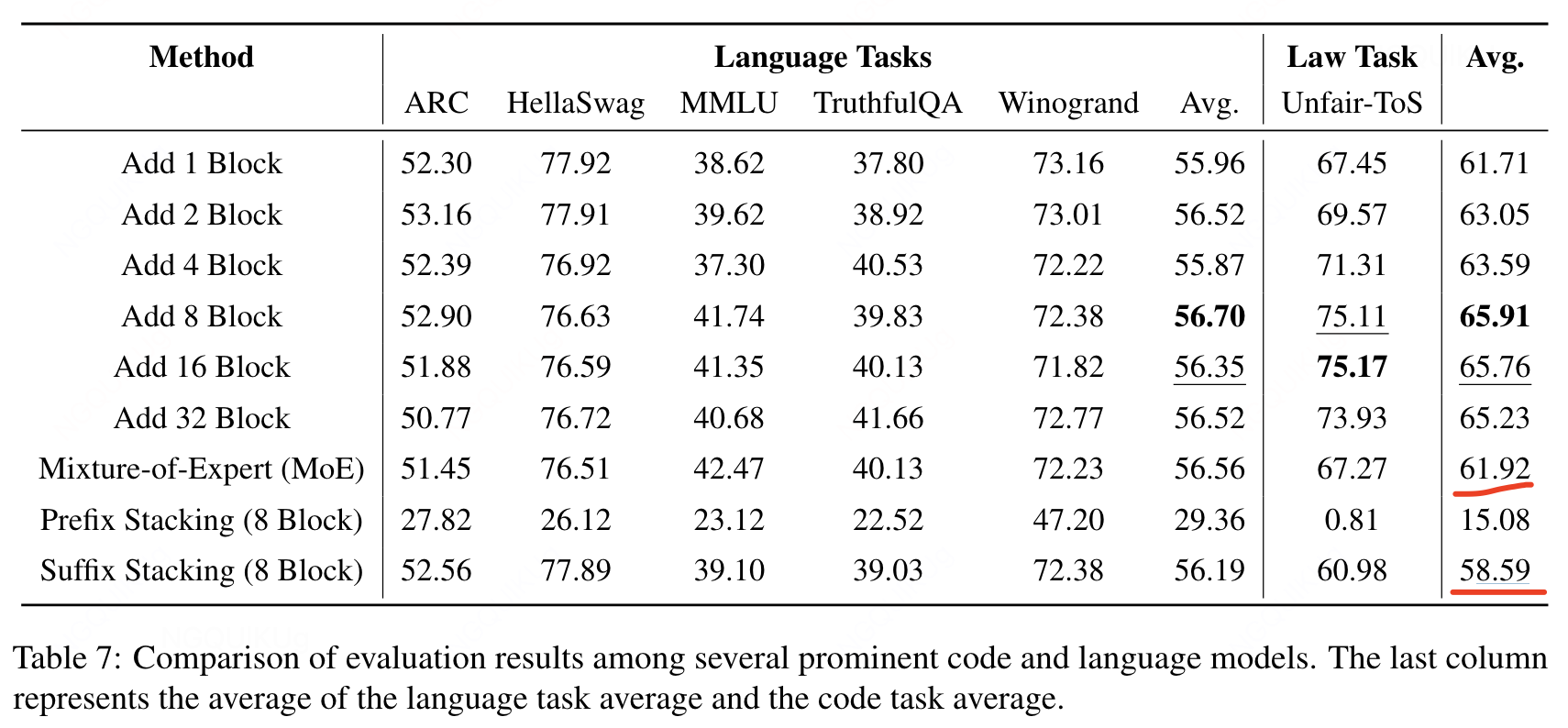
- yi-9b:[2403.04652] Yi: Open Foundation Models by 01.AI
- MASKED STRUCTURAL GROWTH FOR 2X FASTER LANGUAGE MODEL PRE-TRAINING
- MSG用mask的方式做到function-preserving初始化,然后逐步加深加宽训练。

- MSG用mask的方式做到function-preserving初始化,然后逐步加深加宽训练。
- LLAMA PRO: Progressive LLaMA with Block Expansion
- MOE方案
- 仅alignment方案
- 2205.12393
- 2309.11235.pdf
- full Finetune:
- 领域增强:2403.00868.pdf
- Lora、pturning类方案:上限不够高,忽略
- 知识迁移类方案
- 构建大量中英文平行语料,对齐中英conception
- 其他:
- DAP:openreview.net/pdf?id=m_GDIItaI3o
- 多语言学习:2404.04925.pdf
- Investigating Continual Pretraining in Large Language Models: Insights and Implications:主要是domains ct
(i) when the sequence of domains shows semantic similarity, continual pretraining enables LLMs to better specialize in the current domain compared to stand-alone fine-tuning, (ii) training across a diverse range of domains enhances both backward and forward knowledge transfer, and (iii) smaller models are particularly sensitive to continual pretraining, showing the most significant rates of both forgetting and learning.
欢迎交流与合作
目前主要兴趣是探索agent的真正落地,想进一步交流可加微信(微信号:cleezhang),一些自我介绍。