【LLM Review】LLM的问题及当前解决方案 - 2023M6

该篇内容较多,有ppt精简版【LLM Review】The stage review of LLM - PPT - 2023M9
资源汇总:
- This repository contains a hand-curated resources for Prompt Engineering with a focus on Generative Pre-trained Transformer (GPT), ChatGPT, PaLM etc
- GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
一些不成熟的思考
- 关于这波AI技术的影响力:由llm在低推理成本、高准确性上的进展决定。但即使hallucination解决到GPT4的程度止步不前,在AIGC和人机交互上的变革也已经可以提高生产力。
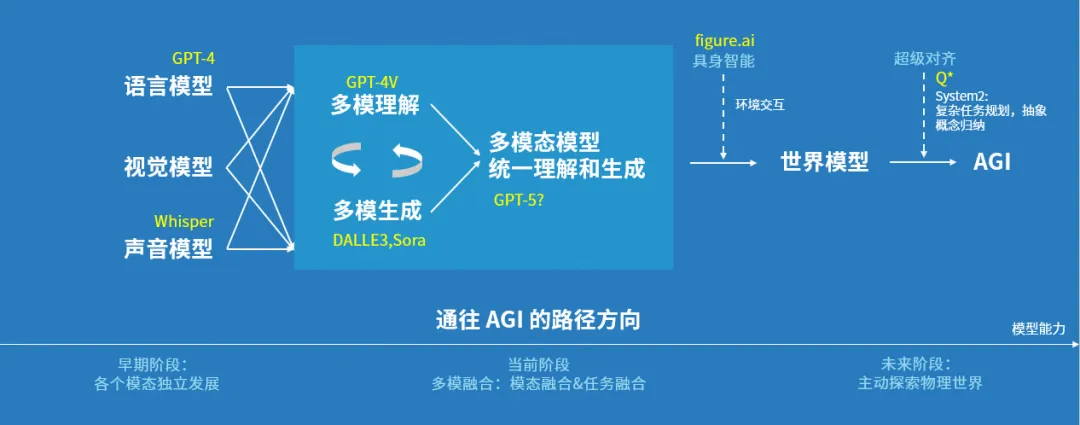
- llm=压缩萃取了人类语言的世界知识库+已经具有自我反思能力+正在学习使用工具的人类大脑+正在学习世界的多模态数据库+将来会拥有像人类一样和其他人(群体智能)以及直接和物理世界实时交互和反馈学习的能力。
- 不要仅仅只把它当做一个知识问答、code生成、多模态内容生成、语音交互的bot.
- llm=压缩萃取了人类语言的世界知识库+已经具有自我反思能力+正在学习使用工具的人类大脑+正在学习世界的多模态数据库+将来会拥有像人类一样和其他人(群体智能)以及直接和物理世界实时交互和反馈学习的能力。
- 关于大模型生态:未来会有多个「基座LLM」,分由多个公司和多个国家提供(类似芯片产业),不会赢家通吃,会有一些行业LLM,中间层也会跑出一些公司,应用层生态目前看LLM-native还比较少,多数是对现有应用的升级改造。
- 关于开源和闭源:闭源商业LLM应该还会至少领先3年+,主要是算力优势、人才优势、先发优势。
- 先发优势:数据飞轮(外部:completion/plugin feedback,内部:GPT4自产数据自训练)、self-learning PPO对抗训练、标准定义权
- 闭源在暗处,可拿来主义
- LLM的商业模式:
- LLM-native/AI+:c.ai,妙鸭、PI-情感沟通、perplexity.ai
- +AI:现有业务是效率或产品升级,更主流
- 注意:技术不能解决所有问题
- 关于未来:
- LLM的「可控性」和准确性问题,如何解决?(前后处理的规则系统,如何完全兜住?判别比生成更容易)
- Tool利用好、多模态LLM训好是当前提升LLM能力最低矮的果实
- Agent/Bot想象力很大,限于当前LLM的能力,从游戏场景开始较合理。多个Agent之间如何协调工作和BP训练?
- 具身智能:如果说Agent更多是LLM+Software,那么具身智能是LLM+Software+机器人(和物理世界交互),类似黑客帝国。
- 能否打破社会壁垒到IT之外的领域去,以更低的成本更好的解决domain问题
一、问题和方案
当前LLM的主要问题包括:1. 准确性,2. 高成本,3. 专业性,4. 时效性,5. 安全性。下面逐一介绍:
-
提高准确性——或降低幻觉:
- 无训练成本:更好的取出知识,可直接集成到LLM的产品pipeline里
- prompt engineering:Prompt Engineer
- System prompt + ICL:设定角色/说明,给出QA示例。
- COT:与ICL结合,在ICL的例子中引入任务拆解过程,让LLM
Think it step by step的做任务拆解,更像人类的方式做reasoning。- 结论:大模型(可能30B以上),复杂推理的任务(数学、常识、符号推理),有比较好的效果,甚至部分task能超过Full FT。
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- constrained Generation(如json)和回答范围:guidance:强制LLM按 固定格式或候选项 生成回答
- task拆分:将task拆分成更多sub-task,请求多次完成
- RAG: 本质是将LLM与传统知识图谱和检索技术相结合,让prompt的内容更准确 ,或限定范围(doc内)的知识抽取并quote。按照是否限定在「检索出的内容内」回答,分为:
- RAG:基于检索返回的内容范围内做回答或Prompt增强:通过 外接doc/book/领域知识库/知识图谱实现。
- Pipeline:
- 召回 chunks:
- ES文本召回
- 向量语义召回(Embedding模型):语义重要是因为「自然问答的长query」
- Break up relevant documents into chunks(如果chunk太大一种方式可以先做摘要)
- Use embedding APls to index chunks into a vector store(ANN向量数据库)
- Given a test-time query, retrieve related information (向量检索)
- Rerank chunks(即精排)
- colbert、cohere等
- 答案生成:
- [optional] 领域微调:chatglm+lora等
- Organize the information into the prompt, get New prompt
- Call LLM using new prompt
- 召回 chunks:
- Openai devday提到的关键优化:
- chunk方式+rerank+prompt设计方式
- 应用场景:ChatXXX,类似「开卷作答」。基于prompt和特定的内容做知识抽取或总结,例如chatXX。有非共识信息的抽取可能有问题。
- quote是个有用的产品设计
- Command R+就是对Command R的RAG和Function call的集成
- Pipeline:
- bing-like:全网通用检索系统搜索+大搜系统检索能力(语义、文本、行为)+轮询多次+Quote
- 先检索bing得到相关文档或文档chunk,和query一起输入LLM分析(若限定文档内知识抽取,则可quote),评估回答,轮询多次获得最优结果。
- 优势:相对外接领域知识库/知识图谱,一是全网信息检索,二是检索不止Embedding语义检索(包括ES文本匹配、LBS和行为等)。
- 其他: perplexity.ai、Google Search Labs
- RAG:基于检索返回的内容范围内做回答或Prompt增强:通过 外接doc/book/领域知识库/知识图谱实现。
- Tools/Function call: offload tasks。LLM和user之间的assistant role,通过调用function role实现
- OpenAI Platform
- Plugins类似PGC,Function call类似UGC,Function可以是任意函数,不用调用工具或API
- 基本plugins:[ 搜索 ]、[ 天气 ]、[ 股票 ]、[ 日期 ]、[ 诗词 ]、[ 字词 ]等
- Retrieval augmented也可以归为这一类
- 多个Function时,LLM通过Function signature/Description做选择的:可制定调特定函数也可auto模式自动选择
- How_to_call_functions_with_chat_models.ipynb
- 观点:openai构建出Plugin生态,接受用户feedback,飞轮转起来,让LLM知道什么时候该去调用什么样的工具。
- Post-processing:
- 类似GAN,增加一个Discriminator得到一个confidence score,做过滤、重新生成或多个选项(放权给用户)。
- 规则:文本或语义相似度超过阈值才能透出
- 产品交互引导:
- 多个选项、Quote/引用原文、引导用户继续输入等。
- Ensemble(多试几次bagging):
- 生成多个答案bagging:Self-Consistency Improves Chain of Thought Reasoning in Language Models
- 输入多个prompt,得到多个答案bagging
- Ensemble refinement:将第一次top k的response的结果与ICL+原始Prompt结合,再请求一次LLM做ensemble。Med-Palm2提出的,感觉不优雅。
- Reflection/System2:XOT
- ToT:Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- ReAct: Synergizing Reasoning and Acting in Language Models
- GoT(该方案有训练成本,放这儿有些不恰当)
- Reflexion: an autonomous agent with dynamic memory and self-reflection (2023)
- prompt engineering:Prompt Engineer
- 有训练成本:
- SFT:称作Instruction FT更合适,有额外训练成本
-
作用:「调教」LLM,按照FT Instructions『特定的形式、样式或规则』生成,包括terse(简洁)、in a given language、consistently format responses (JSON snippets)、custom tone (like business brand voice),shorten their prompts length by up to 90% which speeding up each API call and cutting costs,augment context windows。结合prompt engineering, information retrieval, and function calling会更加强大。LIMA证明Pretrain让model拥有了知识,SFT主要是「调教回答方式」或Alignment。
- 更多的高质量的SFT数据,确实可以让输出更准确、更有帮助f
-
Full FT
-
PEFT:
- Prompt Tuning:训练一个task-specify的embedding input prompt token(包括上层trainable variables),参考【LLM Review】Decrypt Ptuning - 2023W32。
- Lora/Qlora
- Adapter
-
- 增量Pretrain:提高信息压缩比
- Pretrain:更好的数据配比、数据质量、训练技巧、可用的训练资源等都很重要
- DoLa
- 其实有些东西模型知道,清楚的很,但这个清楚知道的太早了
- 这个清楚因为一层层完后跑后,可能会糊涂掉,你需要知道每一层的权重, 嗓门大的别被淹没,让输出能看到
- DoLa
- 研究热点:
- Long Context Window:
- 模型改进:
- 各类外推方案:RoPE(ABF频率调整)、NTK 的 RoPE 可以对 RoPE 的频率进行动态的插值、
- 长序列样本继续预训练、SFT数据用各类长序列数据
- Retentive Network: A Successor to Transformer for Large Language Models
- MQA:Fast Transformer Decoding: One Write-Head is All You Need
- multi-query attention, where the keys and values are shared across all of the different attention "heads", greatly reducing the size of these tensors and hence the memory bandwidth requirements of incremental decoding.
- Scaling Transformer to 1M tokens and beyond with RMT
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
- 编译或硬件
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- 观点:MHSA是一种笛卡尔积式的暴力记忆方式,而人脑会选择记忆(重要性)和归纳整合。
- 模型改进:
- Tokenizer:更好的效果和推理性能
- reasoning优化
- MAmmoTH
- Strong evidence for the relationship between coding and reasoning: when formatting the input as pseudo code + changing the underlying base model to code llama leads to clear performance gain over its language counterpart.
- Most prominent factors are: diversity of questions + code-formated reasoning.
- MAmmoTH
- planning
- Long Context Window:
- SFT:称作Instruction FT更合适,有额外训练成本
- 评价指标: instruction following, factual accuracy, and refusal behavior.
- 更广泛的评价库-the OpenAI Evals library:report shortcomings using models
- 无训练成本:更好的取出知识,可直接集成到LLM的产品pipeline里
-
高成本(GPU固定成本和电量)
- 训练成本:参照Chinchilla scaling laws
- 基座LLM成本成本
- 领域LLM训练成本
- 推理成本:未来更重要,后面0-3年应用展开期会主要卷这个,云厂商等infra很重要
- 算法:
- KD
- MOE
- Speculative decoding:小模型生成,大模型(GPT4)挑选:小模型生成更多top_k或top_p,由大模型得到top_top_k,大模型和小模型异步并发,提高推理效率、降低成本。还有哪些比BS和top_p更高效的采样方案?
- continual batching:实时调整batch大小(有些sample的token已经predict完了)
- 硬件或框架
- tensorrt-llm:NVIDIA TensorRT-LLM Supercharges Large Language Model Inference on NVIDIA H100 GPUs | NVIDIA Technical Blog
- FPGA、AMD Radeon series + ROCm、FlashAttention等
- 算法:
- 训练成本:参照Chinchilla scaling laws
-
专业性:领域垂类LLM,方案参考【LLM Review】如何训练行业大模型 - 2023M8
- 金融:BloombergGPT
- 医疗:Med-Palm2等
- 法律:Chatlaw(值得好好读)
- 心理咨询/情感陪伴:扁鹊、PI
-
时效性:
- Plugins:天气、证券股票
- Retrieval augumented prompt
-
安全性
- SuperAlignment:
- 创建人类水平甚至超级智能的 自动对齐ai系统
- 隐私安全
- 私有数据泄露
- SuperAlignment:
二、Agent
定义:自主或半自主完成一个复杂任务,如autoGPT/GPT engineer等
- 定义:借助大模型,能自主理解、规划、执行复杂任务的系统。
- Agent的中间态应该是「半结构化」的,减少幻觉。
- 利用LLM、Memory和各类Tools/Plugin做task拆分、优先级排序和执行完成复杂任务。agent都是GPT4,但按功能分为Task Creation Agent、Task Prioritization Agent、Task Execution Agent。
- Agent = 大模型+主动规划/拆解+记忆+工具使用
- 大模型:基础,也是当前主要瓶颈
- 主动规划:task自主拆分、task排序、result reflection、人工干预。planning是当前最难的task之一(还有reasoning/数学)
- 记忆:基于长短、重要性的高效记忆和提取。仅向量数据库时不够的
- 工具使用:基于function signature的语义匹配也可以做到基本可用

- Agent分享:LLM + 任务拆解、mem、工具
- gpt-engineer:提供了自动task拆分prompt engineering,和增加了人工干预流程(促进任务细化),logging回溯系统。
- baby AGI:增加了mem(更准确的说是context task)。workflow从<objective, init_task>开始(如果init-task不准确,后面能否纠正过来?)
- AutoGPT:增加了工具调用
- Smallville:
- perception/reflection/planning/act等都是llm生成的
- 难点:
- 时间维度建模问题
三、Embodied Intelligence
四、其他
- 关于训练:
- RLHF:
- RM均匀反馈的问题
- SLiC-HF: Sequence Likelihood Calibration with Human Feedback
- 如何构建训练数据:
- 数据质量
- 数据配比很重要:DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
- RLHF:
- 认识LLM
- LIMA: Less Is More for Alignment
- Evidence of Meaning in Language Models Trained on Program
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
- 中文LLM
欢迎交流与合作
目前主要兴趣是探索agent的真正落地,想进一步交流可加微信(微信号:cleezhang),一些自我介绍。